…but why your tech company won’t tell you that
At the recent DataEngBytes conference in Sydney, most of the 500 people in the room were talking about how to add agentic AI to their stack. Occam founder Steven MacLeod was one of the few who didn’t.
Instead, he stood up and told them: “The modern data stack is a Frankenstein’s monster — stitched from mismatched parts and somehow expected to dance.”
That line got their attention.

Steven MacLeod at the DataEngBytes conference in Sydney
MacLeod wasn’t talking about dashboards or orchestration tools or the latest add-on for cloud pipelines. He was talking about data itself — the stuff that actually sits at the heart of IT.
“The very core of IT, the only reason why it exists, is for operational data. If you remove operational data, all you’re left with is Netflix and Gmail. And yet you can barely find an operational data expert in any IT department — nobody is an expert in it.”
The problem, Steve argued, is that we’re still living in Data 1.0. SAP, designed in the 1970s for mainframes, still dictates the basic structures of how enterprise data is stored.
“Memory was so expensive back then that SAP field names were limited to six-character German abbreviations — which left us with 100,000 tables and two million indecipherable fields,” MacLeod said.
“No-one can memorise it, so SAP programmers need to spend their brain capacity on memorising slop instead of focusing on the job at hand.
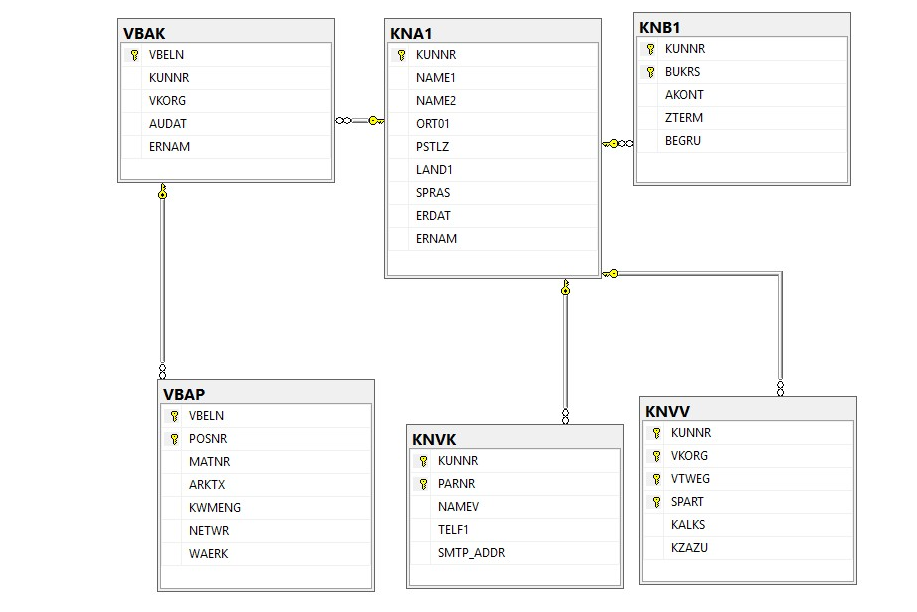
How’s your German? The indecipherable code that underpins most data systems
To make sense of the unreadable data, the industry has created the semantic layer — effectively a second information system whose only purpose is to explain the first one. “That’s the epitome of failure,” Steve said. “Their information system is so bad they have to build another one to explain what the first system is.”
So why doesn’t anyone fix it?
So why doesn’t anyone fix it? Partly because the mess is too big? Partly because too many jobs, products, and consultancies are monetised on patching the mess rather than replacing it.
Everybody’s fiddling at the edges,” MacLeod said. “Because to really fix it you have to throw everything out and start again.” And yet agentic AI, the very thing everyone in that room was excited about, is what makes fixing it unavoidable.
“AI works with human language. When it looks at fields called KUNNR or VKORG, it has absolutely no idea what they mean.” You can try to teach it by adding more complexity with a semantic layer, but every customisation adds more costs and delay.
“This is why SAP projects that are planned to take two years, but often end up taking four, will now take five years,” he said. “It’s not just the work, it’s the number of people involved, which adds exponential complexity.”
Crappy, poorly designed and badly named operational information systems are the reason most Agentic AI projects are failing. MacLeod says the problem is that AI cannot fudge its way through this data labyrinth — in the same way humans can’t. If the data isn’t clear, AI will hallucinate or fail. That’s why, in MacLeod’s view, Data 2.0 is not optional — it’s urgently required.
Ontology-Native
“Data 2.0 starts with being ontology-native. This isn’t ontology as documentation — it’s ontology as execution. A single canonical record of business logic that generates every layer of the system,” MacLeod explains.
“Ontology-native means defining the logic of the business in one place and using that to auto-generate all the layers of the software stack: database, code, UI, ETL and analytics. All based on the same core ontology (expressed in plain English), so agentic AI can fully embrace and work with all the layers of the stack — not just horizontally across the data lifecycle between the operational data and analytical data, but also vertically through the entire software stack.
Done properly, ontology-native information systems are spectacularly more productive — literally a 100x improvement in our ability to get work done with data.
MacLeod goes as far as to say that with ontology-native design, it is now faster, cheaper and lower risk to build bespoke systems that meet your exact needs than it is to implement 50-year-old off-the-shelf systems and endless customisations.
Enter Data 2.0
Ironically, the pushback to this change will come from the software industry, not the client. For downstream customers, the shift will barely register. They won’t see the plumbing. What they will see are systems that are delivered in months instead of years, systems that actually agree on what a “customer” is, and systems that cost $1–2 million instead of $50 million.
“That’s why we need Data 2.0,” MacLeod says.
“Because the moment you buy an off-the-shelf system, it’s already100% technical debt. With Data 2.0, you get the opposite. You get speed, clarity, and cost savings on a scale people don’t yet believe is possible.
“Data 1.0 was a huge achievement. But it’s a prototype and it’s a mess. It’s time to rebuild it so that it actually works to our modern expectations — and unlocks the true value of your data for the benefit of all.”
To contact Steven MacLeod, find him on Linked In or at Occam.works

