Occam founder Steven MacLeod took the stage at the recent #DataEngBytes Conference in Sydney with a stark message: Data 2.0 is coming, and it will trigger one of the biggest structural shifts the industry has ever faced. Here’s the key insight from his presentation:
At the DataEngBytes conference in Sydney, Steven MacLeod didn’t come to reassure the room. He came to remind them that the foundations of the modern data stack are broken — and that pretending otherwise only delays the inevitable.
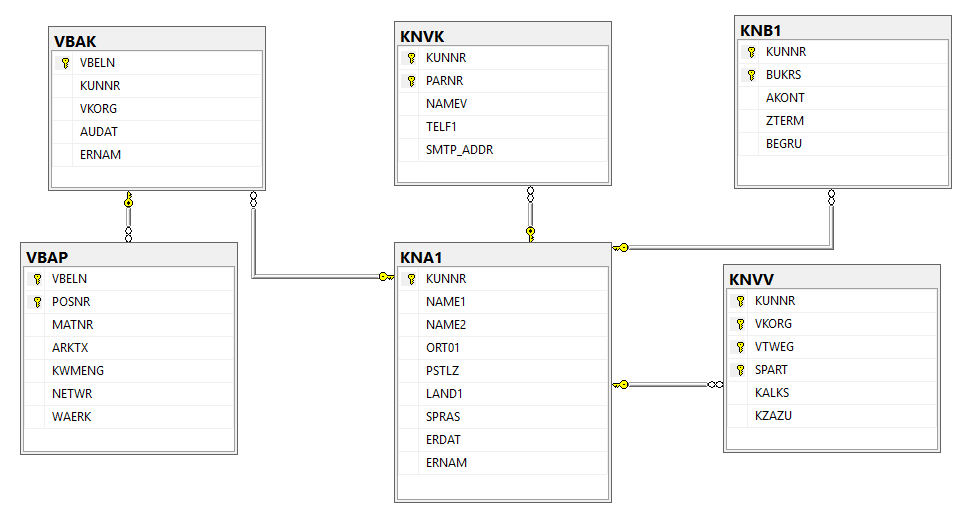
“The modern data stack has thirteen categories of software just to convert operational data into analytical data,” he said. “And every arrow you see in those diagrams — every little arrow — is a problem. It’s an API, an ETL, an integration process. Each one hides technical debt that, in many cases, exceeds the market capitalisation of the company.”
Every arrow in a consultant’s diagram is an obstacle and a source of cost and complexity.
Vendors show slides filled with tidy icons and smooth arrows. MacLeod sees each of them as obstacles. “Pick any one of those arrows and it represents mega information systems, dozens of industry systems, and thousands of Excel spreadsheets. And all of that has to be held together with manual synchronisation. That is why projects blow out in time and cost,” he said.
“Every new orchestration tool, every patch, every “solution” adds another layer to the backlog.”
For the vendors, consultants and coders who live in the middle of the stack, this complexity has become their business model. Every new orchestration tool, every patch, every “solution” adds another layer to the backlog. But the same middle layer that generates revenue is also the pinch point that AI is about to obliterate.
At the very nexus of all of IT lies operational data — “take it away and all you’re left with is Netflix and Gmail,” MacLeod says. “Yet, the bedrock of the IT industry has spent half a century avoiding it.
“It’s locked in. The data engineer can’t touch it. The software engineer hasn’t shown much interest in learning the rules of data. And, management seldom has a deep knowledge of operational data. So, nobody is an expert in it.”
That immovable core forces everything else to be layered on top. Dashboards. User interfaces. Scripts. Orchestration. The industry’s answer is to add yet another layer — the semantic layer — to explain what the first layer means.
“Most information system designs are so bad that they require a second information system, just to explain how the first system works,” MacLeod says. “Software vendors say they will provide you with a single version of the truth and they can’t even achieve this with their own system. That’s the epitome of failure.”
Which is why he insists the problem cannot be solved incrementally. “We’re going to have to stop building and take an honest look at ourselves and the value proposition that Data 1.0 delivers.”
And why the urgency? Agentic AI makes that unavoidable.
“There’s no consistency of naming across the software stack, so AI has absolutely no hope of making sense of it.”
“Using Agentic AI against the modern data stack it simply won’t scale,” he said. “There’s no consistency of naming across the software stack, so AI has absolutely no hope of making sense of it. Agentic AI needs human language to work but information systems are using anything but that.”
“With Data 1.0, every layer of the stack is describing the logic of the business in a different software language, using different software tools, written by different people. And as we’re quickly finding out, without clean foundations, AI hallucinates or fails.

Steven MacLeod speaking at #DataEngBytes
That’s why MacLeod argues it’s time for a complete cleanout — to replace the stack with new foundations of data, what he calls Data 2.0.
“The future is to describe your business logic once, in human language, in an ontology-native model. From there we auto-generate the code for your UI, your mobile app, your reporting tool, your ETL, your warehouse. Fifteen to twenty different places — all fully synchronised, all the time.”
“Armies of consultants and vendors who’ve built empires around nursing the 13-layer stack will quietly become irrelevant.”
For customers, the shift will feel unremarkable. They won’t see the semantic layers being wheeled out to landfill, they’ll just see systems show up faster, cheaper, and that actually make sense. The real spectacle will be in the industry itself. The armies of consultants and vendors who’ve built empires around nursing the 13-layer stack will quietly become irrelevant.
Data engineering, MacLeod reminded the audience, is barely thirty years old. In engineering terms, that’s infancy.
“We’ve had thousands of years to learn how to build bridges,” he said. “We’ve barely started learning how to build data. The change that’s coming won’t just be in the AI tools at the top of the stack. It will be in the foundations — in the way we store, structure and manipulate data itself. And the industry needs to be ready.”
To contact Steven MacLeod, find him on Linked In or at Occam.works